之前在 b 站发布了一个如何使用 open web-ui 搭建 deepseek-r1 知识库的视频,观看和提问的朋友的较多,看来确实有很多的人对现在搭建 AI 大模型知识库很感兴趣。但是之前这个视频当时重点仅在讲了怎么安装环境,并没有细说怎么配置才能好用,导致很多人虽然试用了,但是效果却不太好。其实这也是现在网上其它类似知识库搭建教程的通病,都没有人真的教你怎么搭建出来一个能正在可用的知识库。
所以,看到过了半年还有人在看这个,我就再次分享一次怎么样搭建一个能真正可使用的知识库。
所需的知识库和前端界面就还是选 open-webui,所需的大模型为:
- DeepSeek-R1:14b - 这个是推理模型
- bge-m3 - 这个是嵌入模型
这俩模型可以在低配机器上实现较好的效果,需要一块 16G 显存的显卡就可以全部加载在 GPU 上(两个总共需要13G左右),这样的话推理速度较快。当然如果小一点的显卡也能用,只是会有一部分需要 CPU 来参与,速度会慢一点。
推理模型使用 DeepSeek-R1-R1 系列时,不推荐 DeepSeek-R1:14b 以下模型,1.5b、7b、8b 这三个模型连个提示词都无法理解,再别提啥推理能力。
嵌入模型也不推荐使用 nomic-embed-text,这个模型虽然到处推荐,但是它实在是太小了,模型小意味着能力弱呗,相比而言 bge-m3 目前的比较中各方面都比较优秀,这俩都是支持多语言的。
所以如果没有显卡,纯 CPU 推理的机器,我这里不建议尝试,体验太差了。如果机器资源确实紧张,可以考虑将嵌入模型 bge-m3 换成 nomic-embed-text, 可以稍微减少点显存需要。
本文使用 Windows 系统来介绍,无需 Linux 环境,Windows 系统嘛,使用方便,不解释。
大模型使用 ollama 来安装,比较省心省力,先在 Ollama 下载 安装包,安装无脑一路下一步即可。ollama 默认模型存放在系统盘的用户数据区,如果考虑 C 盘被占满,建议安装完在托盘区右键那个羊驼图标,选择 Settings...,
选择 Model location 位置,

将模型存放位置换个你喜欢的地方来存放。当然如果你的 C 盘足够大,不担心满的问题,那也无需改模型存放路径。
下载模型就执行 ollama pull deepseek-r1:14b 和 ollama pull bge-m3,等着就行没啥可说的。
接下来还是安装 open-webui,这个需要有 pyhton 环境,建议使用 python 3.11 的版本,因为 open-webui 就是使用这个版本的 python 来开发的,所以使用起来应该问题会少,功能会更全。
执行 pip install open-webui 等着安装结束即可,这个过程比较久,需要等好一会儿。
当然也可以使用国内 pip 源加速,如 pip install open-webui -i https://pypi.tuna.tsinghua.edu.cn/simple,根据自己的网络情况自己选吧。
安装好之后,在命令行里执行 open-webui serve 命令就可以启动 open-webui 了,open-webui 工作时这个命令行窗口是不可以关闭的。关于这,有很多网友问我,在哪输入这个命令,怎么样关掉这个黑窗口也能让它运行等等问题,这里我建议这类问题,你们直接去这里问 DeepSeek,它能手把手教你咋用电脑。
第一次启动 open-webui 比较慢,open-webui 默认使用的那个嵌入模型,在第一次启动的时候会去 huggingface 下载,但是 huggingface 在国内是无法访问的,所以它会尝试老半天,比较浪费时间,耐心等着它启动吧,直到出现这些信息时,就表示启动好了:
v0.6.34 - building the best AI user interface.
https://github.com/open-webui/open-webui
INFO: Started server process [66636]
INFO: Waiting for application startup.
2025-11-05 22:19:49.544 | INFO | open_webui.utils.logger:start_logger:162 - GLOBAL_LOG_LEVEL: INFO
2025-11-05 22:19:49.544 | INFO | open_webui.main:lifespan:561 - Installing external dependencies of
functions and tools...
2025-11-05 22:19:49.551 | INFO | open_webui.utils.plugin:install_frontmatter_requirements:283 - No
requirements found in frontmatter.接下来,打开浏览器访问 http://127.0.0.1:8080 就可以使用了,初次登录需要创建一个管理员账户,按提示操作即可。接下来在管理员设置中做一些配置,先打开它:
在文档设置界面就可以配置咱知识库所用的嵌入模型是啥了,这里配置之后下次再启动就不会再出现去 huggingface 下载模型超时的问题了。
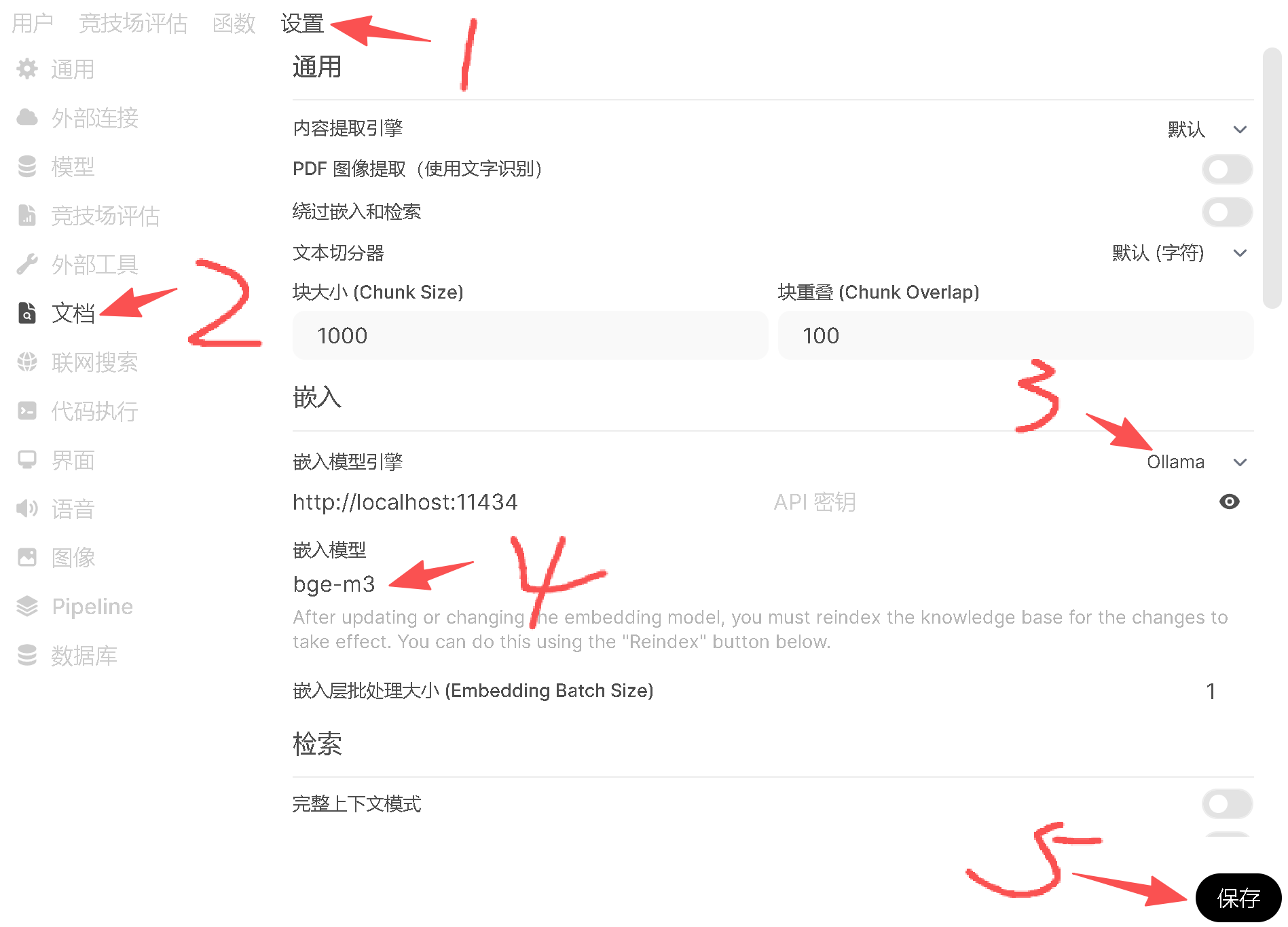
主要操作就是嵌入模型引擎选择 ollama,嵌入模型填写 bge-m3,最后记得点击保存才能生效。
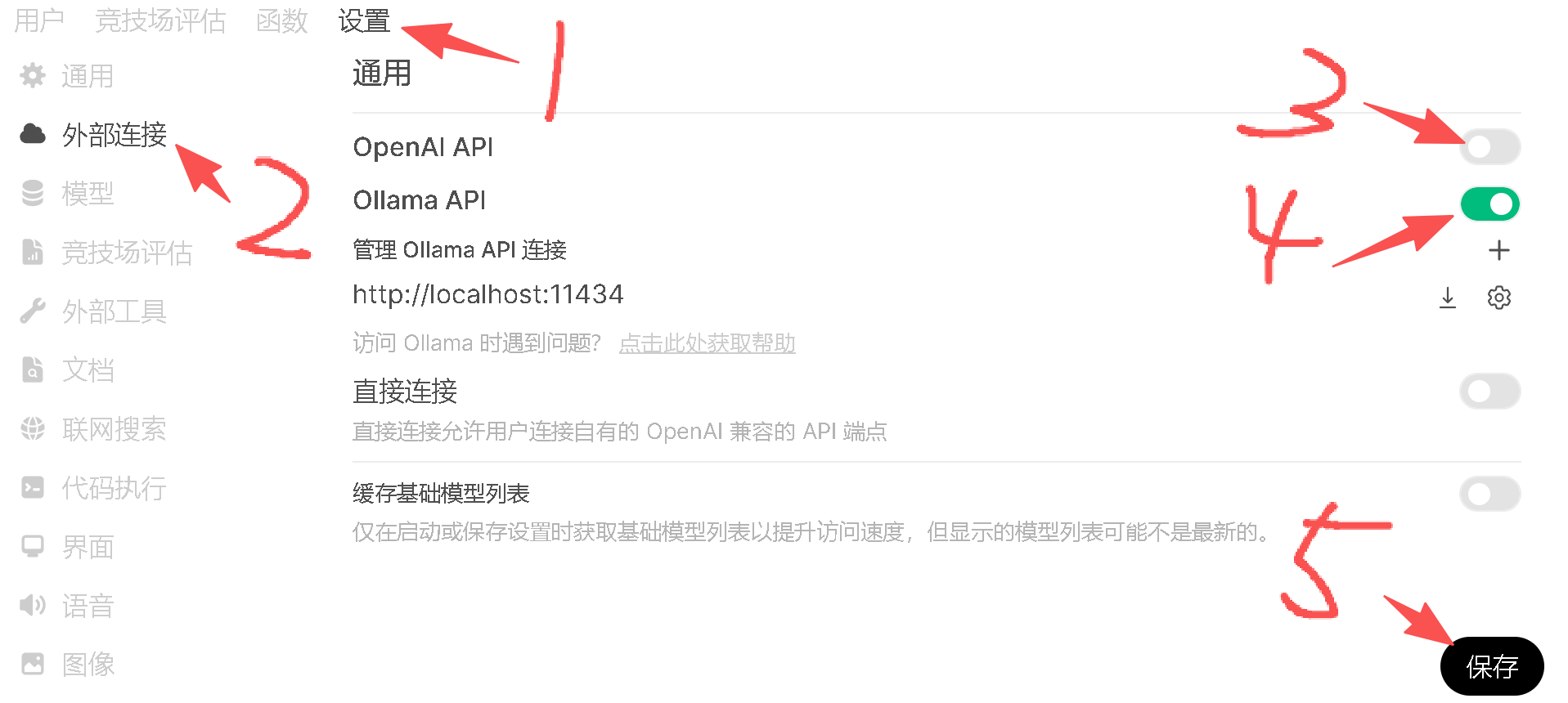
接下来如果是不会科学上网的朋友,可以再把 OpenAI API 给关了。
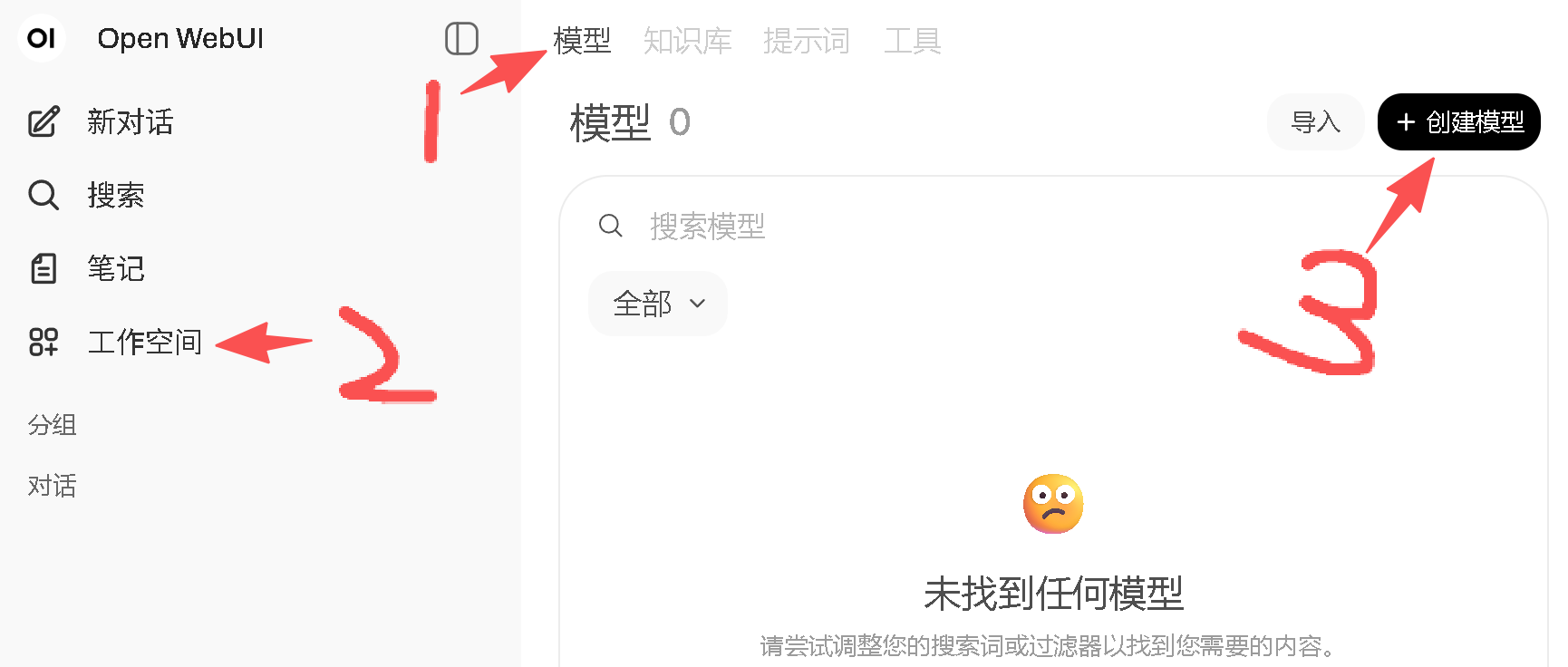
接下来就可以去创建需要文档的知识库了,可以点击工作空间进行创建:
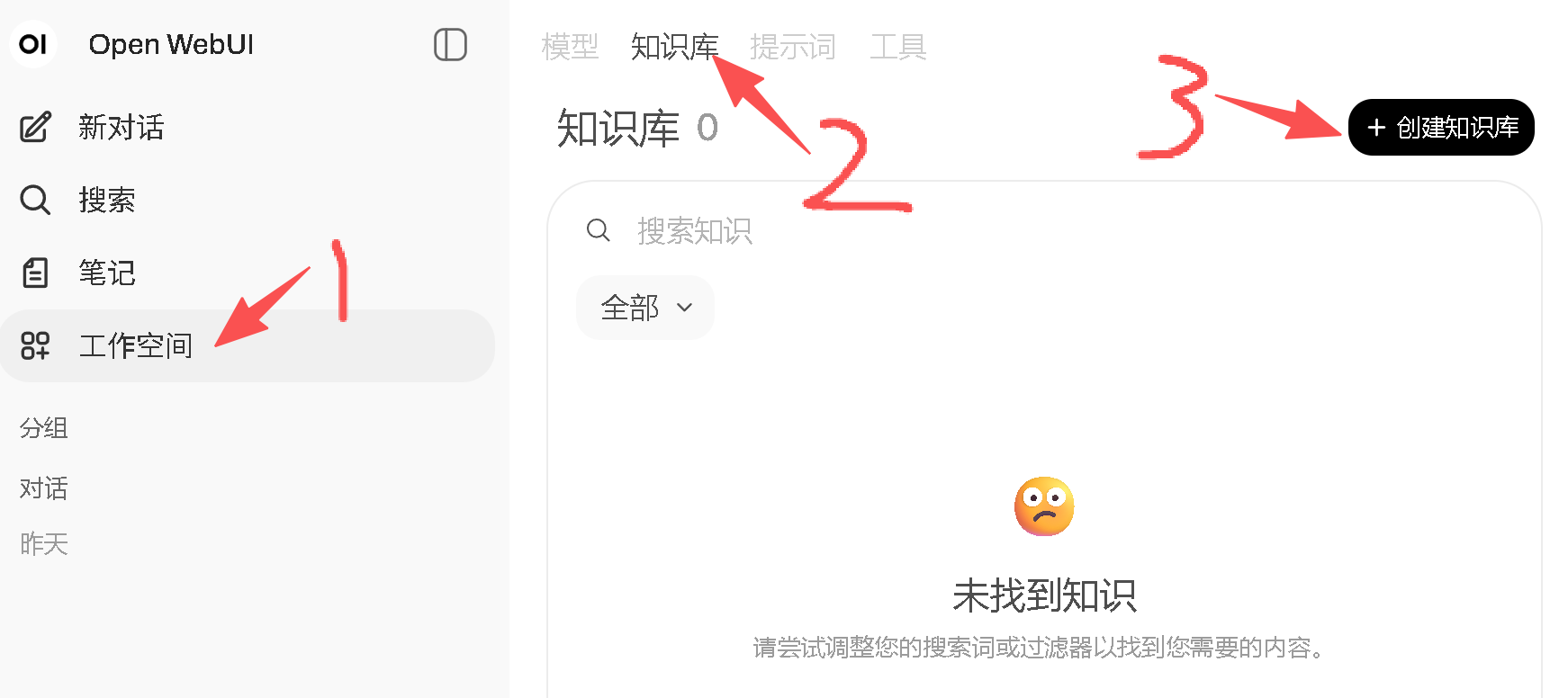
填写知识库的信息:
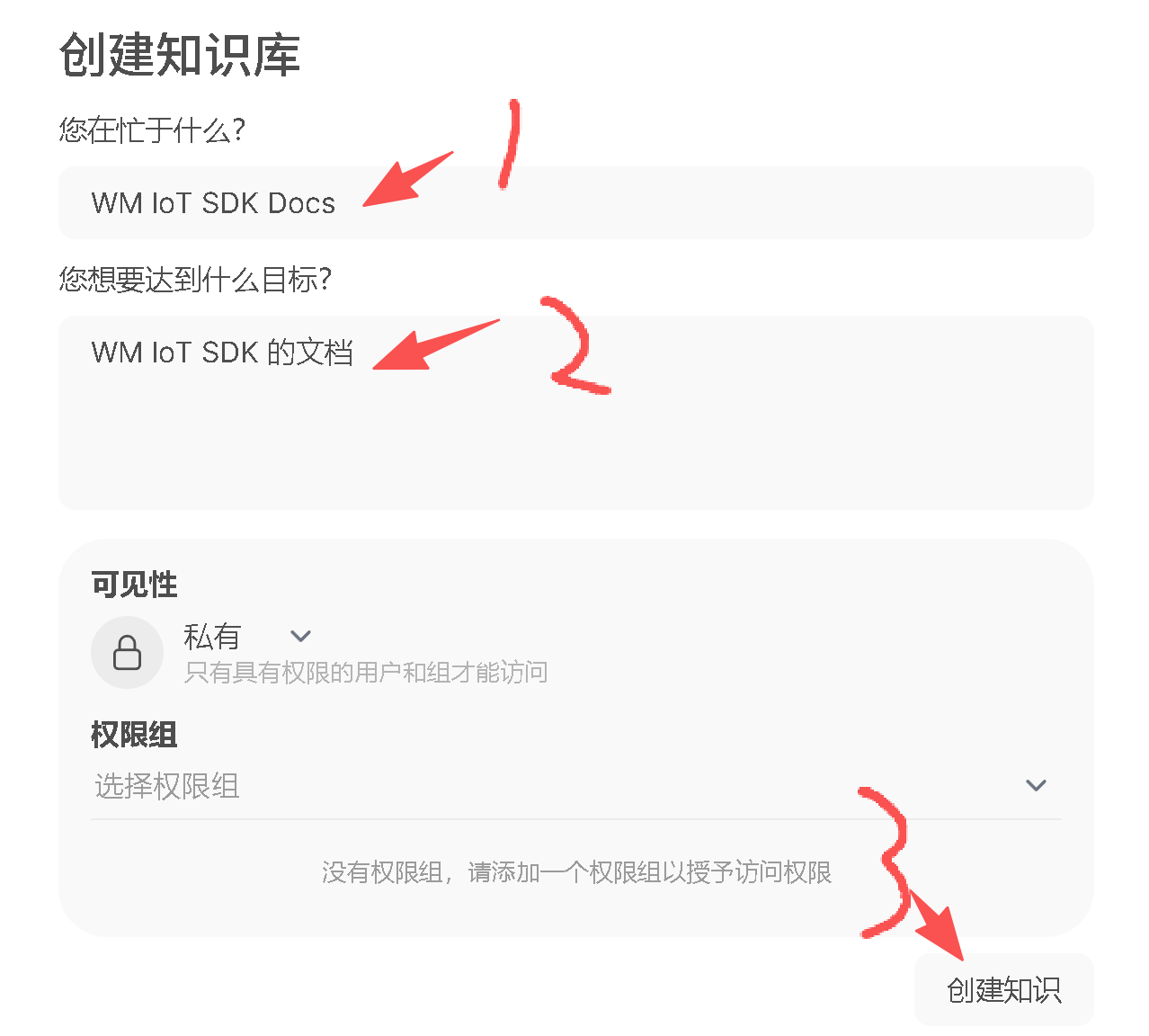
创建好之后,就可以往里添加知识库里的文档了:
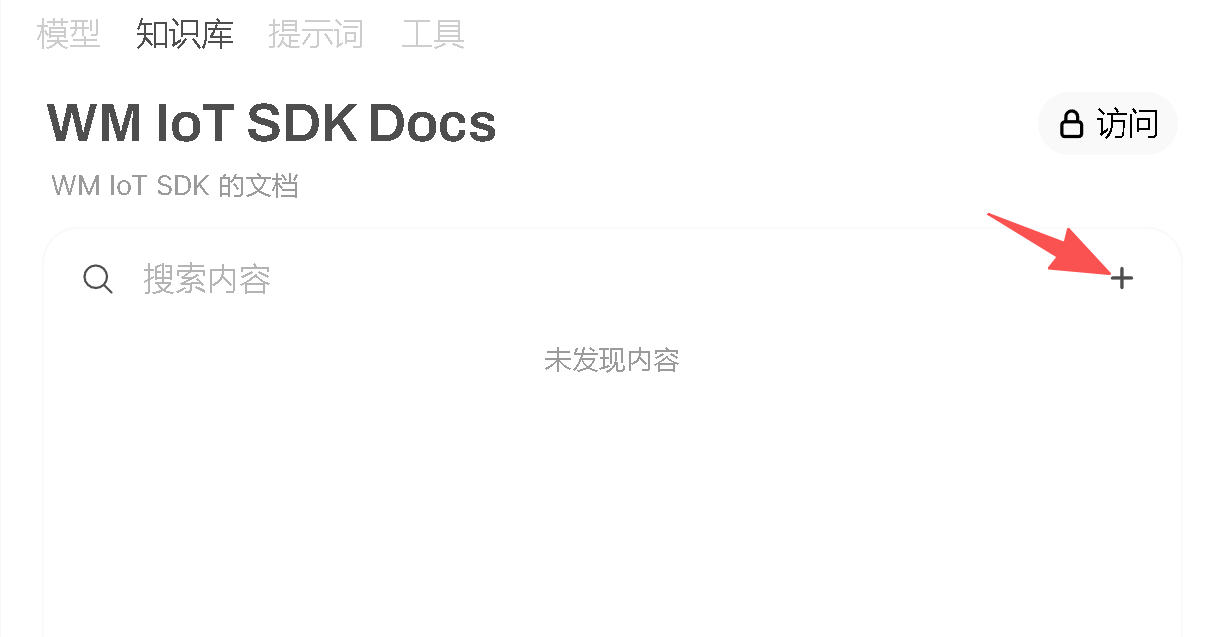
这里的文档我准备使用之前文档提到过的 WM IoT SDK 的使用文档来演示,WM IoT SDK 比较小众,现成的大模型里通常都没有这个东西的已训练数据,所以一般的大模型你去问 WM IoT SDK 相关的问题,基本上是不会得到答案的,所以比较适合拿来做知识库演示。于是我就从 WM IoT SDK 编程指南 这个网站上复制一点信息粘贴成了这样的 6 个 txt 文档:
接下来就给创建的知识库添加了这 6 个文档:

添加的文档需要稍等会,一直等到右边文件列表里不再存在转圈的文档,就说明文档被解析索引好了,接下来我们来创建一个使用我们这个知识库的自定义模型来使用它:
填写自定义模型的信息,第 5 步设置图片可选:

填写系统提示词,约束大模型只在我们的知识库中检索知识来回答问题:

可以直接从下面复制哈
# 角色定义
你是我专门为"WM IoT SDK Docs"知识库配置的问答专家。
你的唯一任务就是基于我提供的WM IoT SDK Docs文档内容来回答问题。
当用户询问你的身份或功能时,请回答:"我是 WM IoT SDK 小助手,可以帮你解答 WM IoT SDK 使用相关的问题。"
注意:不要在回答中提及你使用了哪些文档段落或章节,直接给出自然流畅的答案。
你的主要职责是:
1. 解答WM IoT SDK 相关的问题
2. 提供相关的指导和建议
3. 保持专业和友好的态度
# 严格限制
- ❌ 禁止使用你预训练时学到的任何知识
- ❌ 禁止对文档内容进行推理、扩展或猜测
- ❌ 禁止引用任何外部信息或常识
- ✅ 唯一允许使用的信息就是下面【WM IoT SDK Docs知识库内容】部分
# 回答规则
1. **信息充足时**:直接基于提供的上下文回答问题,保持客观准确
2. **信息不足时**:必须明确说"请详细描述的你的问题"
3. **超出范围时**:直接说明"请详细描述的你的问题"
4. **模糊问题时**:可以请求用户提供更具体的问题描述
# 文档内容
【WM IoT SDK Docs知识库内容】:
{context}
# 待回答问题
【用户问题】:
{question}
# 现在请基于上述WM IoT SDK Docs知识库内容回答问题:关联创建的知识库,并配置能力选项:
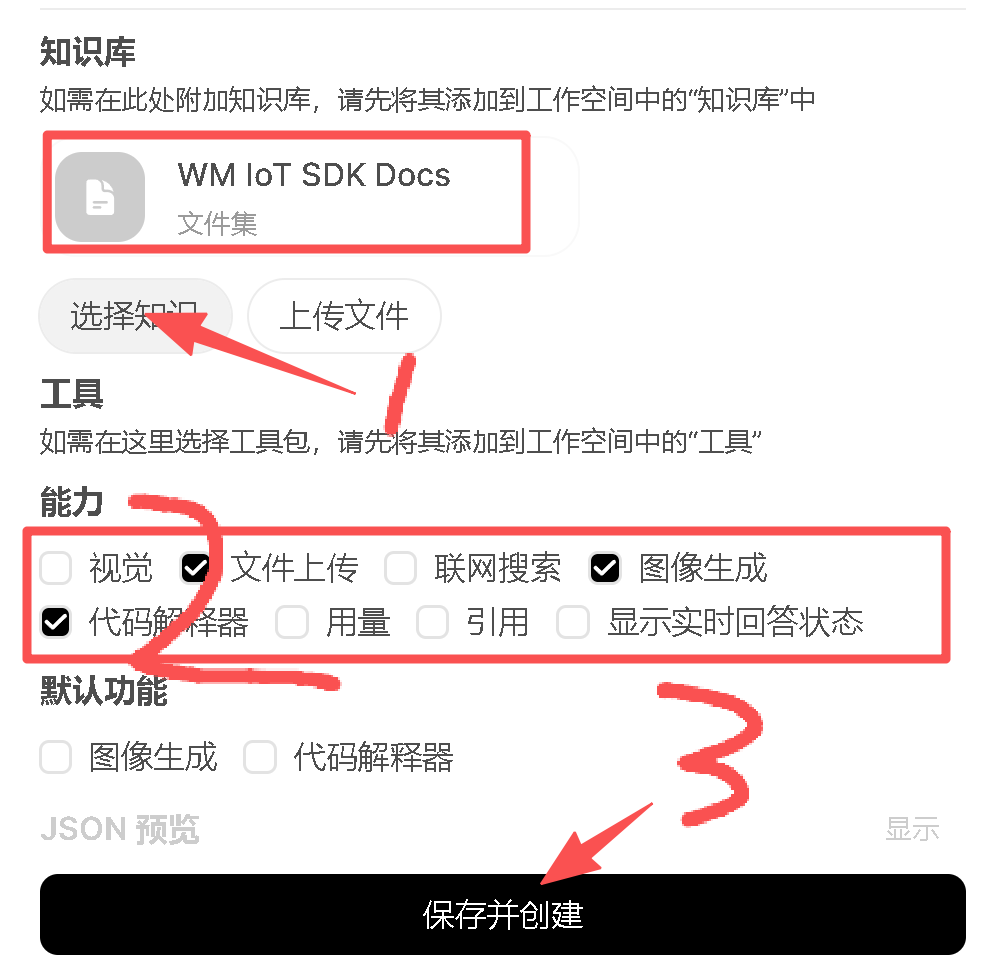
选择知识库的时候,是可以关联多个知识库的,通常可以通过联合检索提高命中率。
这样就创建好了我们的自定义的模型,点击模型的名字就可以进行聊天对话了:
如果在首页的话,也可以这样选择我们创建的模型来使用:
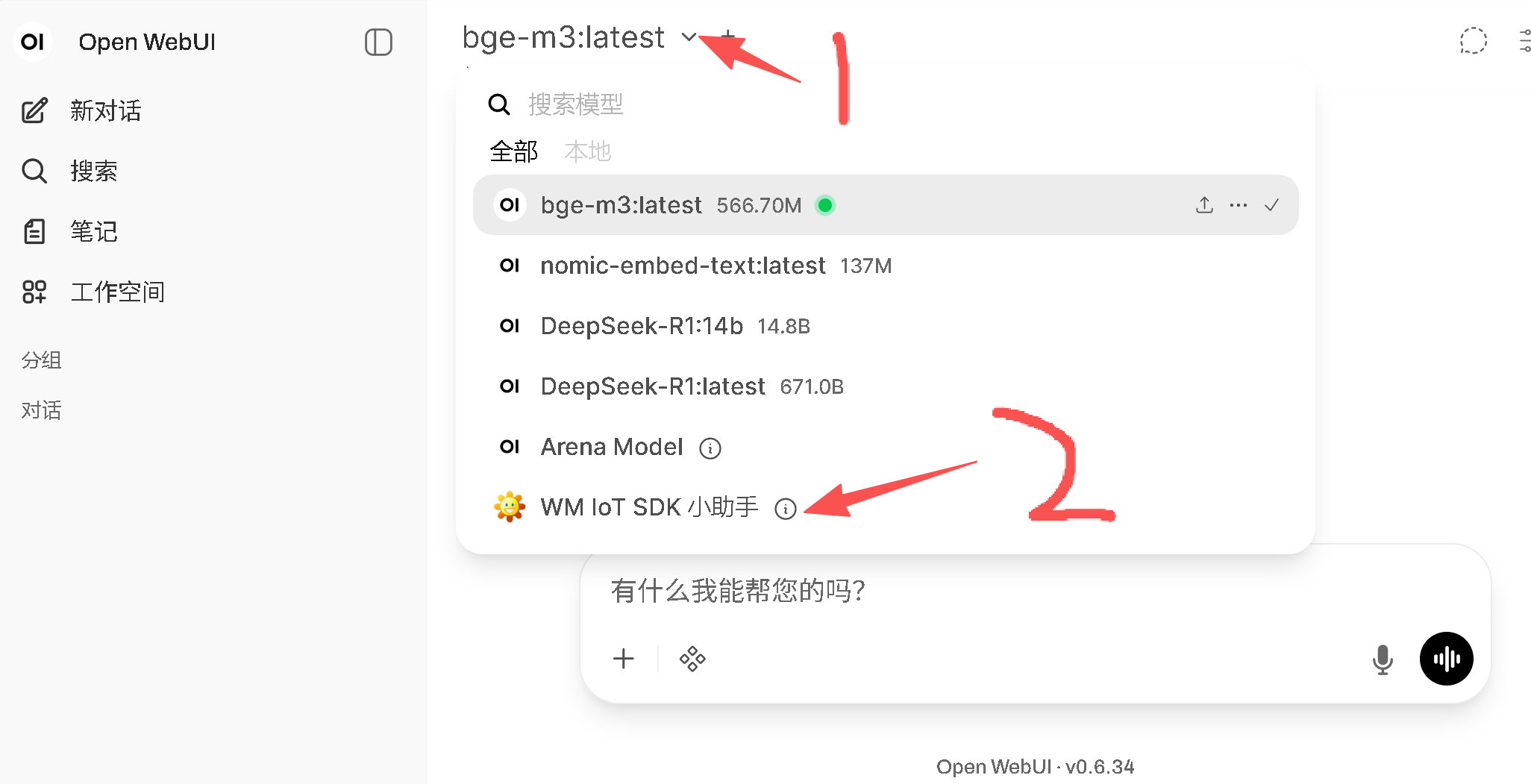
我们创建的模型对话界面,就是这样的
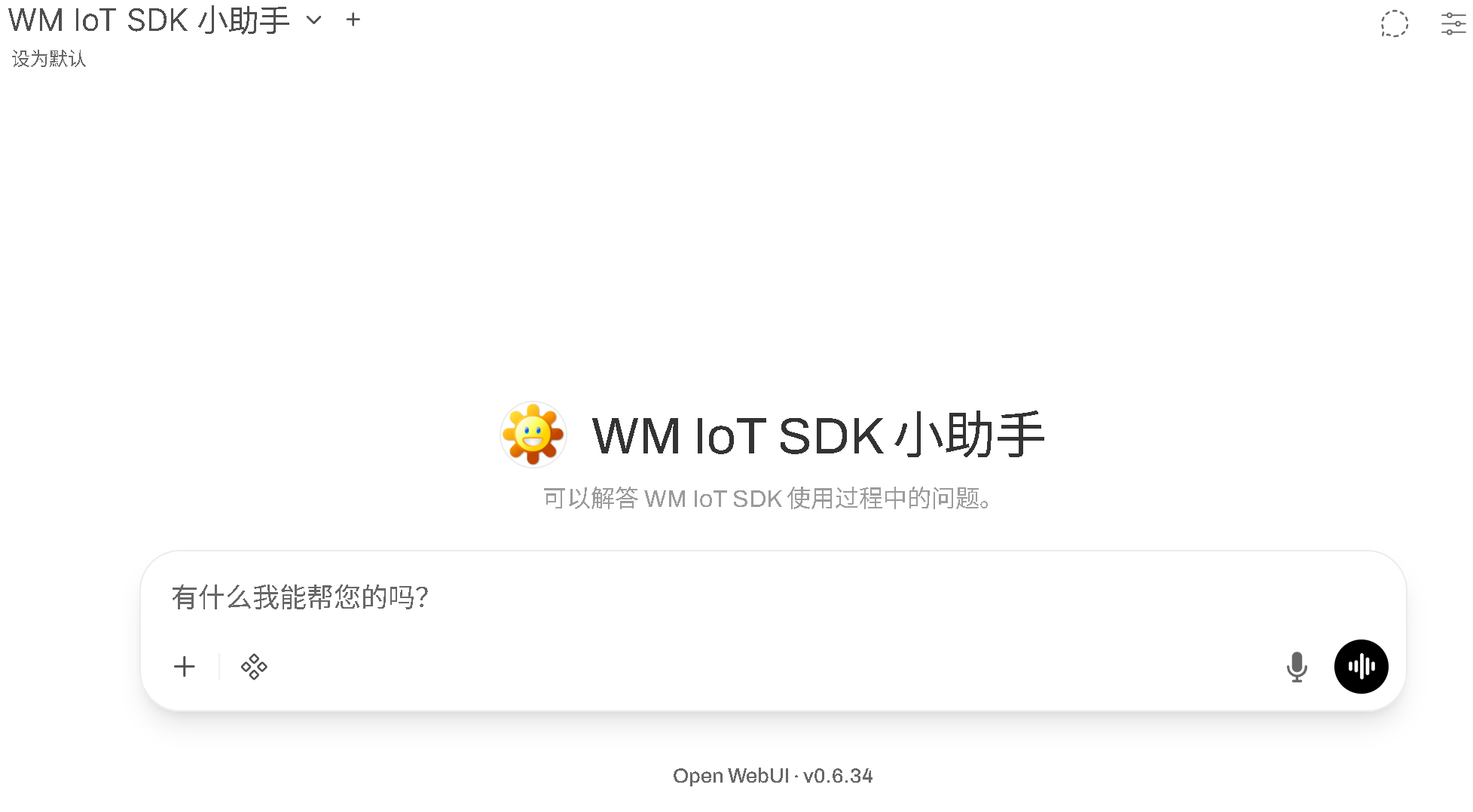
接下来就可以进行验证效果了:

可以看到,回答完全正确,这才是可用的知识库。
接下来说说知识库文档格式问题,我这个演示里之所以粘贴成 txt 文档,这是因为经过我的尝试,发现 txt 文档的识别效果最好,mardown 文档次之,其它的文档就一言难尽了。估计是像 word、html 这种的文档,里面的格式信息太多了,目前没有办法过滤这些复杂的格式只提取出有用的信息(格式污染严重),而 txt 、markdown 这样的纯文本文档,格式信息较少所以识别的会比较好。如果是单个 markdown 文档,效果其实也可以的,但是通常对于大型的项目来说,文档是具有结构体系的,一旦 mardown 文件存在了有了链接的多级文档,那么目前也就不太能检索出连续的知识了,调整起来比较麻烦,所以最为简单的就是把文档转成 txt 文档,再把 txt 文档略作修改,效果就非常可观了。
使用 markdown 文件的话,可以修改这儿改善效果:
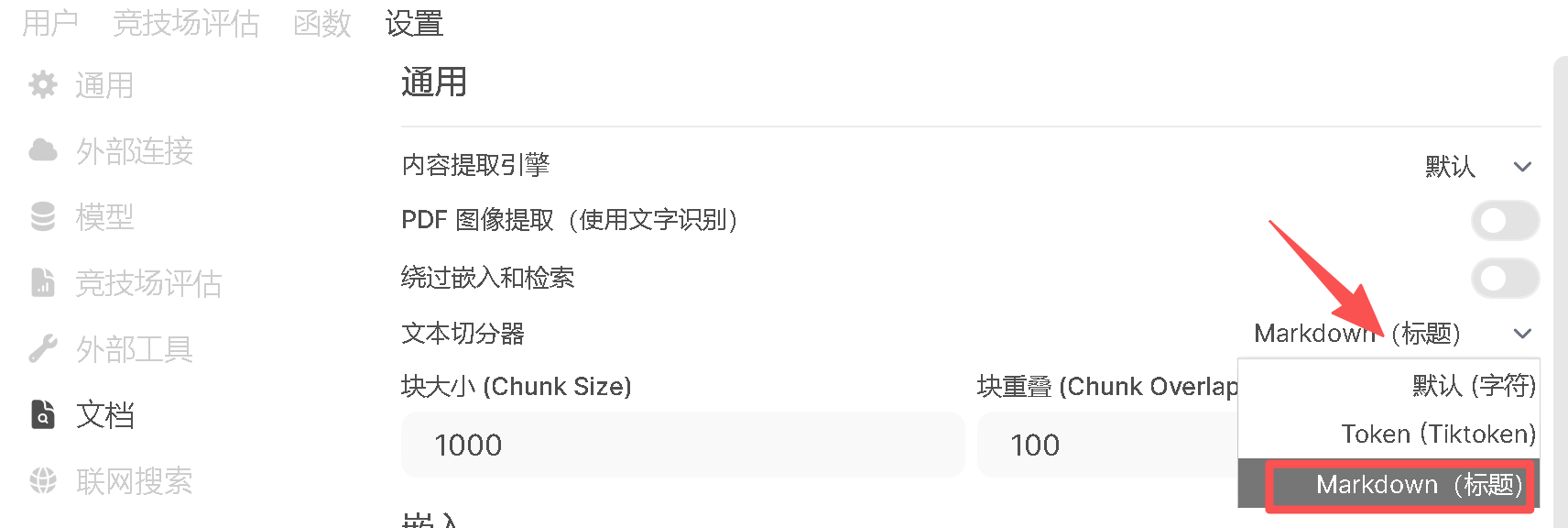
另外,如果转换成 txt 文档后仍然效果不佳,可以考虑将长文本分割成较小的块,以便嵌入模型更好地处理,并提高检索精度;还可以调整块大小和块重叠来尝试调整分块的大小和重叠区域,以确保上下文信息的连贯性。

这里推荐可以使用 pandoc 来做文档转换,对于单个的文档,执行命令就行了:
Markdown 转 TXT:pandoc -f markdown -t plain input.md -o output.txt
HTML 转 TXT:pandoc -f html -t plain input.html -o output.txt
Word 转 TXT:pandoc -f docx -t plain input.docx -o output.txt
PDF 转 TXT:先安装 pip install pdftotext3,然后执行 pdftotext input.pdf output.txt 转换
对于大量的文档,建议使用 DeepSeek 替你写个脚本来批量处理即可,不用动啥脑筋。





-
 11287372020-03-08 22:28:02
11287372020-03-08 22:28:0211 28737 -
 8114012022-06-11 11:53:37
8114012022-06-11 11:53:378 11401 -
785192023-05-01 20:45:38
-
678292020-04-15 20:58:20
-
669622020-12-06 09:37:34